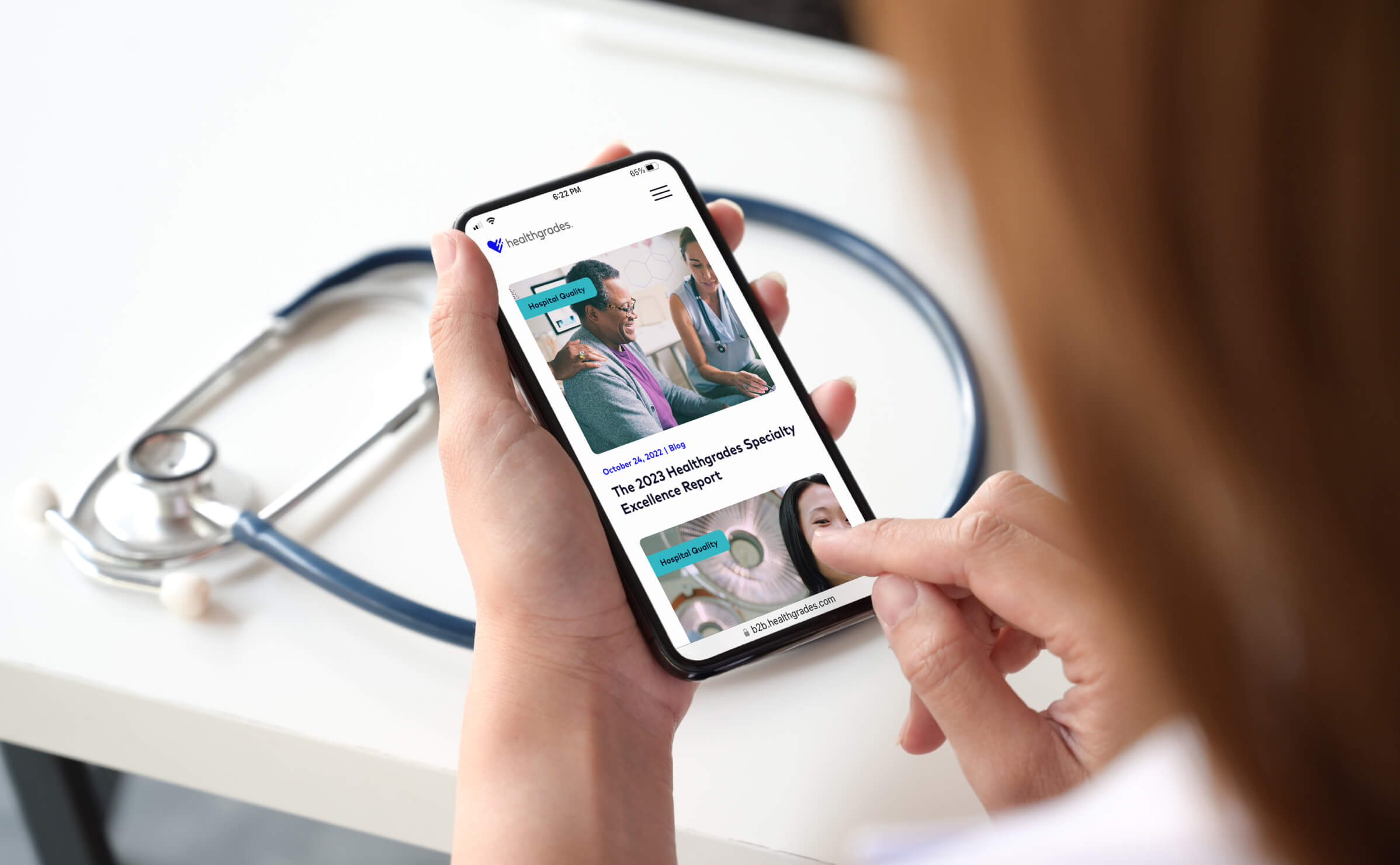
we are terra
A global marketing agency built for the digital world.
Terra is your guide to the global digital terrain.
























We're honored by the recognition of our team's outstanding work in marketing and communications.

Category Winner
2023 Best Annual Report

3x Winner
Fastest Growing U.S. Companies

Honorable Mention
Exceptional Web Design
“Terra is essential to Airbnb's communications strategy for millions of hosts.”

Vanessa Schneider
Director of Host Operations, Airbnb



Platinum Winner
Digital Media

Gold Winner
Paid Social Campaign

2X Winner
"Site of the Day"
Ways we help
You’ve got goals. We’ve got the team to help you reach them. What should we work on together?
Check out our work
We partner with brands of all shapes and sizes to deliver ambitious digital projects and results.